


With the constant technological advances, we now face daily challenges to decide which technology is more advanced and efficient. Cloud, edge computing, and fog computing are a few technological advances made over the years.
Edge computing and fog computing make it possible to solve the problem of latency between data collection and transmission and bandwidth issues. Both edge computing and fog computing receive the same amount of attention these days but are often misunderstood by those who need to learn their differences.
These terms can be pretty confusing regarding which one is what. To help you wrap your head around this topic, we wanted to give a good overview of what these terms mean across the computer networking spectrum.
What is Edge Computing?
Edge computing is moving some computing tasks to the edge of a network close to where the data originates.
Edge computing is moving IT services closer to the data creation or consumption source. This can be done by distributing servers, storage, and processing resources at the network edge or in a cloud data center co-located with an organization’s network edge.
Edge computing is being adopted to support the proliferation of IoT devices and applications – especially those requiring real-time processing capabilities. The growth in IoT connectivity has been enabled by 5G mobile networks, low-cost sensors, and connected devices.
Edge computing has many benefits, including:
- Greatly reduced latency and improved performance for applications that require low latency responses (e.g., autonomous vehicles)
- Reduced network congestion by reducing traffic sent over the WAN or cellular networks
- Improved privacy by allowing customers to keep their data on their systems instead of sending it to cloud providers’ servers
What is Fog Computing?
Fog computing is a new computing model where cloud and edge devices work together to meet applications’ performance, latency, and scalability requirements.
The market for fog computing seems bright over the next five years. The market for fog computing was valued at USD 65.05 million in 2016 and is expected to grow at a CAGR of 58.94% from 2017 to 2028 to reach USD 1048.6 million.
In fog computing model, cloud-based services are distributed across multiple nodes at the network edge. These nodes can be either standalone devices or compute instances within fog gateways. The fog computing environment provides key benefits:
- Provides low latency for quick responses
- Enhances data privacy and security
- Ensures resilient operations with redundancy
- Efficiently utilizes network bandwidth
- Enables Real-time decision making
- Delivers better network reliability
Fog computing enables you to deploy applications closer to end users, which reduces network congestion and improves performance for those applications.
The Similarities between Edge and Fog Computing
Edge computing and fog computing share several similarities due to their common goal of bringing data processing closer to the source of generation. Here are some key similarities:
- Distributed Processing: Both edge and fog computing involve distributing processing tasks away from centralized cloud servers and closer to the data source. This minimizes the need to transmit large amounts of data over long distances, reducing latency and improving response times.
- Latency Reduction: Both paradigms aim to reduce latency by processing data locally or near the source. This is critical for applications that require real-time or near-real-time responses, such as industrial automation, autonomous vehicles, and healthcare monitoring.
- Bandwidth Efficiency: By processing data locally, edge and fog computing help alleviate the strain on network bandwidth. Only refined or relevant data needs to be transmitted to central servers, reducing the overall data transfer volume.
- Real-Time Decision-Making: Both concepts enable real-time edge or fog-level decision-making. This is crucial for applications where immediate actions need to be taken based on the data generated by sensors, devices, or IoT endpoints.
- Support for IoT: Both approaches are well-suited for IoT applications where many devices generate data. They facilitate data management, processing, and communication from various IoT devices.
- Privacy and Security: Both edge and fog computing enhance privacy and security by keeping sensitive data closer to the source and minimizing data exposure during transmission. This is particularly important for applications that deal with personal or sensitive information.
- Redundancy and Reliability: Both paradigms can improve system reliability by distributing processing across multiple devices or nodes. If one node fails, others can continue processing, reducing the impact of single points of failure.
- Flexibility in Applications: Both edge and fog computing can be applied to a wide range of industries and applications, including manufacturing, healthcare, transportation, agriculture, smart cities, and more.
- Hybrid Architectures: Both paradigms can complement cloud computing rather than replace it. Hybrid architectures that combine edge, fog, and cloud computing can offer the advantages of each approach while catering to different processing and storage needs.
Edge Computing vs. Fog Computing
The terms fog computing and edge computing are often used interchangeably, but they are different.
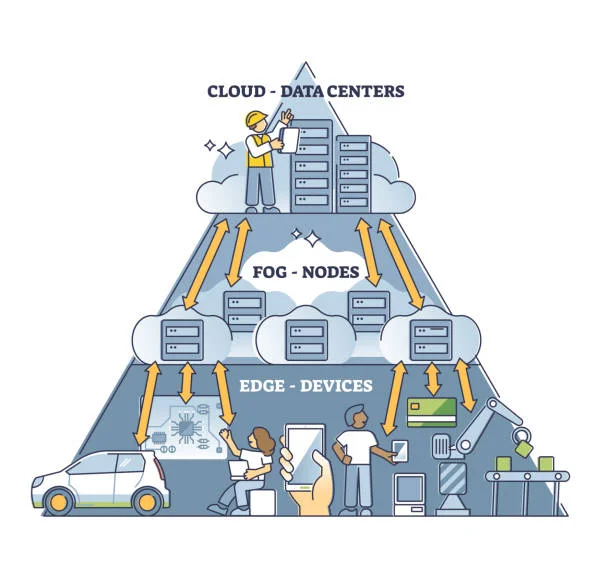
The two concepts are related, but they have different uses.
| Aspect | Edge Computing | Cloud Computing |
| Definition | Edge computing refers to processing data at or near the data source, typically at the network’s edge. It involves deploying computing resources (like servers or gateways) closer to the data source. | Fog computing refers to a decentralized computing paradigm in which data is processed in a more distributed manner, typically at the edge devices themselves or in nearby “fog nodes.” |
| Distance from Source | Processing occurs at the immediate device or gateway level, just a few meters from the data source. | Processing occurs slightly farther away from the data source than edge computing, often involving nearby fog nodes or micro data centers. |
| Scope | Primarily focused on a single device or gateway. | Focuses on a cluster of devices, gateways, or sensors that are geographically closer to each other. |
| Latency | Offers lower latency since processing happens extremely close to the data source, reducing the time it takes for data to travel. | Offers relatively low latency as well, but it might be slightly higher compared to edge computing due to the involvement of fog nodes. |
| Resource Availability | Limited resources available at the edge device or gateway, potentially leading to constrained processing capabilities. | Slightly more resources available at fog nodes compared to individual edge devices, allowing for more complex computations. |
| Scalability | Scalability can be a challenge due to the limitations of individual edge devices. | Offers better scalability due to the presence of fog nodes, which can distribute the computational load. |
| Data Processing | Primarily performs simple or preliminary data processing and filtering before sending refined data to the cloud. | Performs more substantial data processing, aggregation, and filtering compared to edge computing. |
| Data Storage | Typically involves minimal local storage due to resource constraints. | May involve slightly more storage capacity at fog nodes, enabling them to temporarily store and process data. |
| Network Dependence | Heavily relies on low-latency and stable networks to transmit processed data to the cloud for further analysis. | Relies on relatively stable networks as well, but some processing can be done within the fog network itself. |
| Use Cases | Well-suited for scenarios where immediate processing and response are critical, such as real-time monitoring and control systems. | Suitable for applications that require intermediate-level processing, such as smart cities, industrial automation, and healthcare monitoring. |
| Architecture | Emphasizes a more device-centric architecture, with edge nodes directly connected to data sources. | Focuses on a hierarchical architecture with edge devices connecting to fog nodes, and fog nodes connecting to the cloud. |
| Management | Management of individual edge devices can be complex due to the distributed nature. | Offers a more centralized management approach through fog nodes, making it easier to manage and monitor multiple devices. |
Can the Same Hardware Work for Both Fog Computing and Edge Computing?
Regarding the hardware and computers you can use, edge computing hardware can serve the same role as a fog server. The distinction lies in how and where data is gathered and processed rather than the hardware’s features.
Take the Karbon 800 as an example, designed for edge computing – it’s also fitting for fog computing. Remember, each project is distinct. Choosing and setting up hardware should consider your project’s specific needs.
Edge or Fog: Which Computing Method is Best?
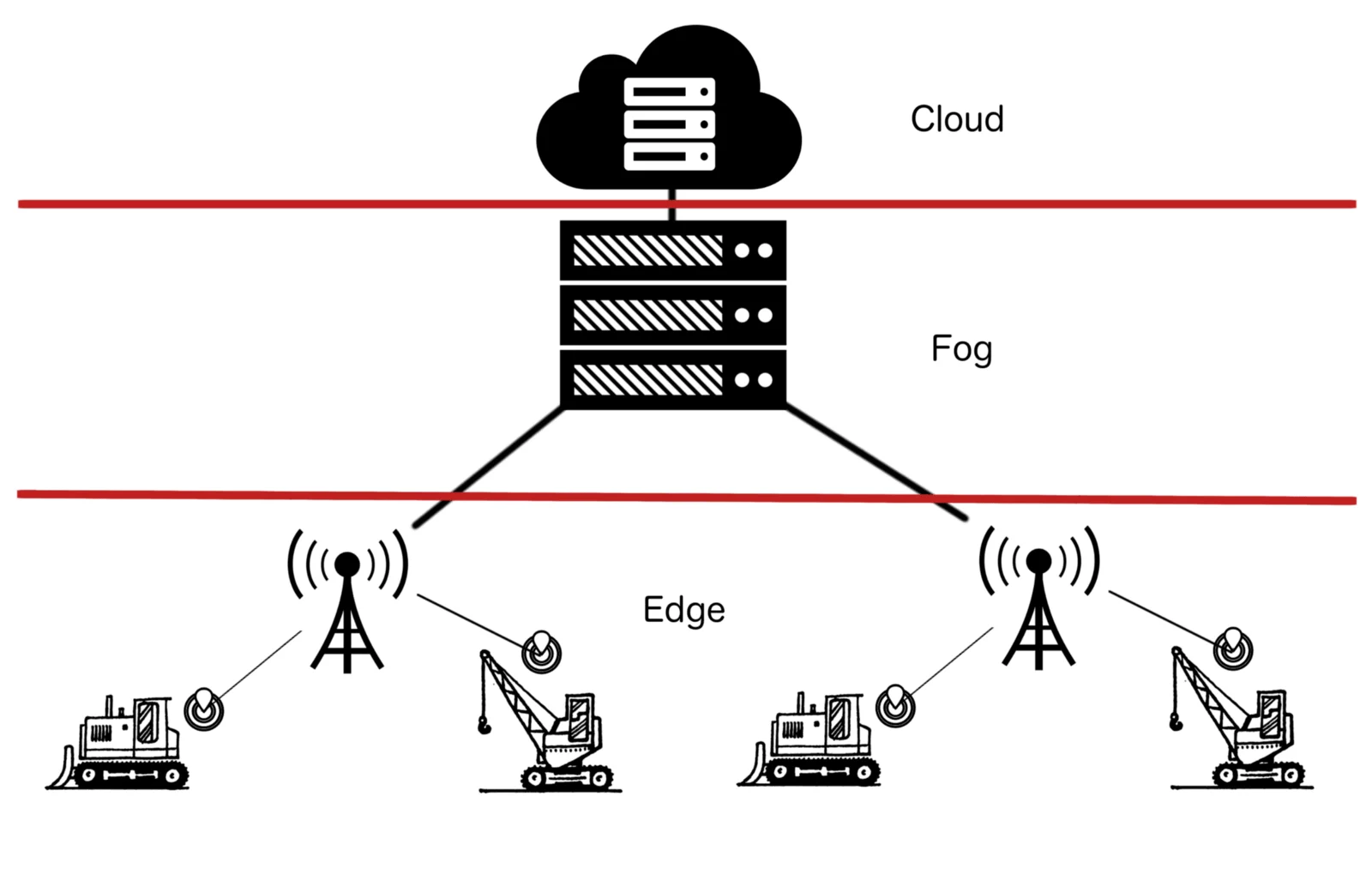
Edge and fog computing are modern technology approaches that are gaining popularity. They both bring computing power closer to where data is created rather than relying on big central data centers far away.
If you’re considering costs, Edge computing is usually cheaper, especially if you’re using pre-built solutions from big companies. Starting up with fog computing can be pricier because it requires extra hardware. Fog computing uses both Edge and cloud resources.
Edge computing can handle business data and send the results to the cloud. It can work without fog computing. But fog computing can’t work by itself because it doesn’t create data; it needs Edge computing. Both methods are great because they improve user experiences, help data move smoothly, and reduce delays.
Taikun: Navigating the Divide Between Edge Computing and Fog Computing
In wrapping up our exploration of the differences between Edge Computing and Fog Computing, it’s evident that both concepts are revolutionizing how we process and utilize data.
To seamlessly integrate these cutting-edge approaches into your operations, turn to Taikun. Taikun offers real-time monitoring, automated CI/CD pipeline creation, and optimized management as a cloud automation platform designed to supercharge your DevOps teams.
Elevate your productivity, user experiences, security, and data protection. Explore Taikun today for free or consult with our experts to receive personalized guidance.